



Reading Ambitiously 10-25-24
The Wall Street Journal once used ‘Read Ambitiously’ as a slogan, but it became a challenge I took to heart. If that old slogan still speaks to you, this weekly curated newsletter is for you. Every week, I will summarize the most important and impactful headlines across technology, finance, and enterprise SaaS. Together, we can read with an intent to grow, always be learning, and refine our lens to spot the best opportunities. To quote Jamie Dimon: “Great leaders are readers.”
In the news:
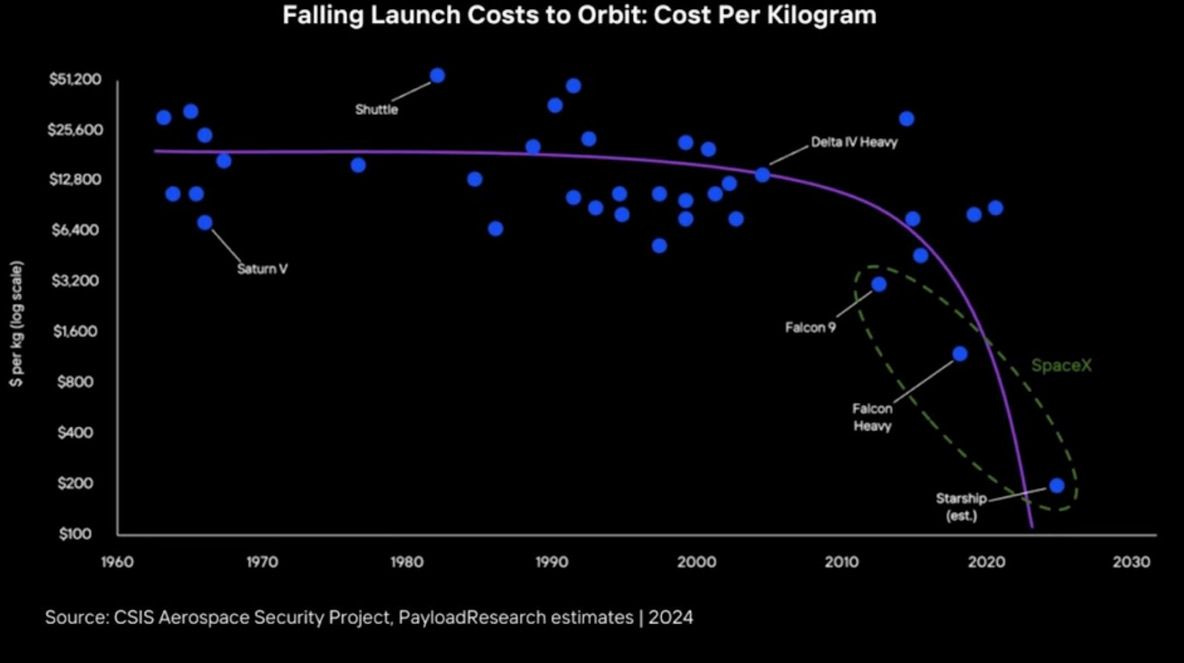
→ Why does it matter? At Base Camp 2023, we spoke with Lori Garver, former NASA Director under President Obama, who played a key role in establishing partnerships with SpaceX and Blue Origin. When we first met, Lori shared a thought that stuck with me: the most important goal in space exploration is reducing the cost of getting to space, while the real value lies in what happens “in orbit.” Convincing NASA to collaborate with private companies wasn’t easy, but Lori and her team knew the potential benefits were too significant to overlook. Here’s a chart we created to illustrate that.

Last week, SpaceX successfully caught a Starship booster before it crashed, allowing it to be reused. This achievement significantly lowers the cost of launching, reducing the price of sending 1 kilogram of material into orbit by an order of magnitude. See chart! 🤯
Best of the rest:
📱 Anthropic’s new AI can control your PC - TechCrunch
🎨 Generative AI’s Act One: The Era of Creation - Sequoia Capital
📧 The Messy Inbox Problem & AI Apps Wedge Strategies - a16z
💰 All Revenue is Not Created Equal: The Keys to the 10x Revenue Club - Above the Crowd
🚀 Scaling from $1M to $20M ARR - ICONIQ Capital
💼 The $14 Billion Question Dividing OpenAI and Microsoft - The Wall Street Journal
🌍 Google and Kairos Power Sign Agreement to Advance Nuclear Energy - Google Blog
Charts that caught my eye:
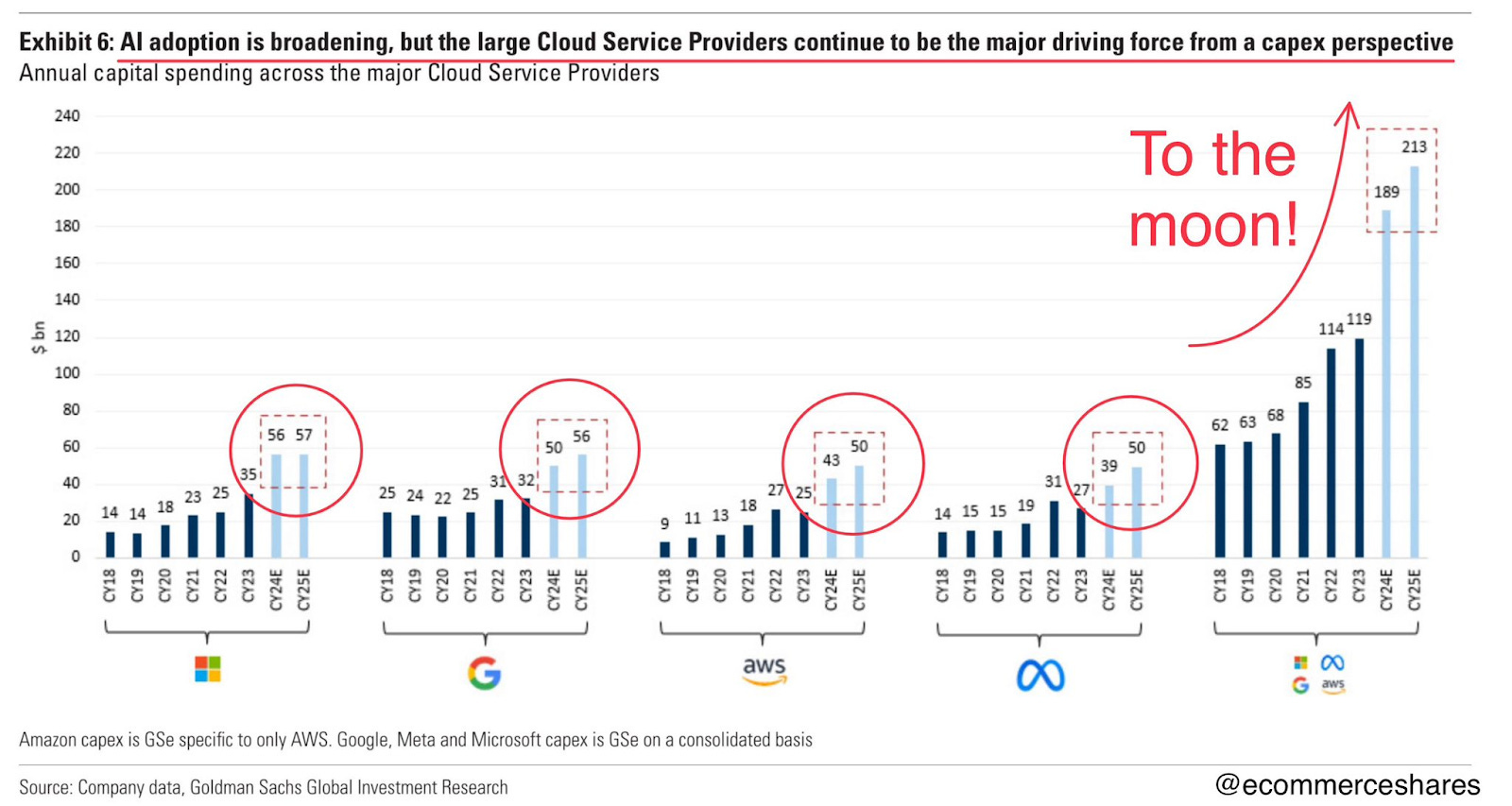
→ Why does it matter? 46% of Nvidia’s revenues came from just four customers. 🤯
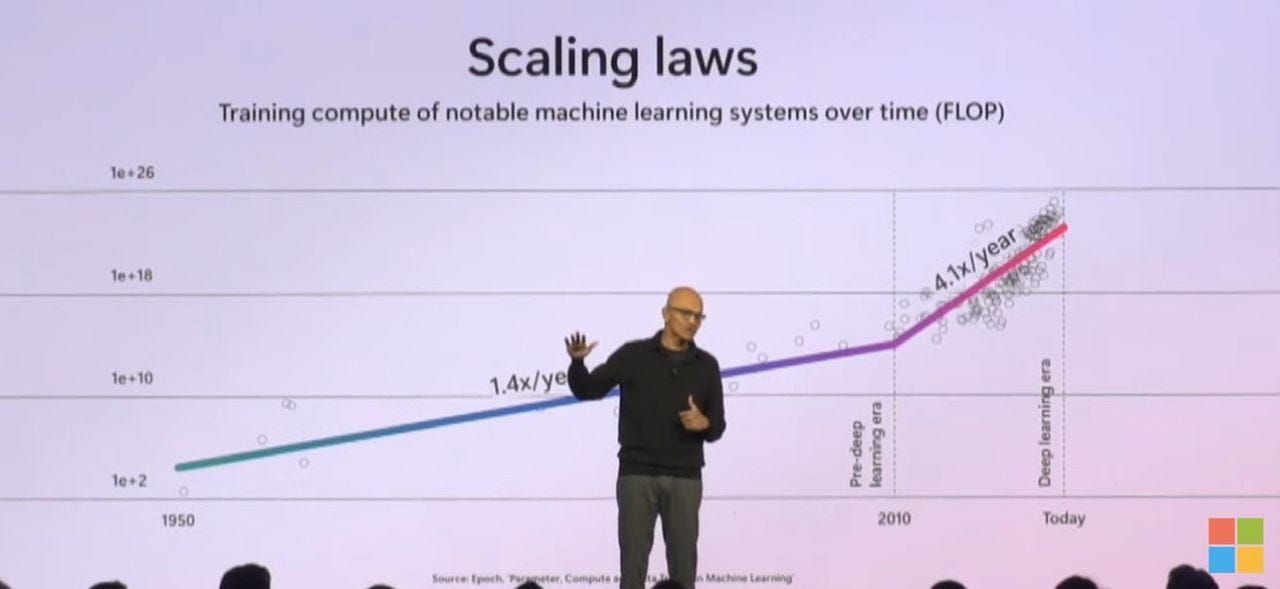

→ Why does it matter? This is from Microsoft’s AI Tour Keynote. Microsoft is on the bleeding edge of describing how enterprises are going to interact with AI-enabled systems. I love that second chart with the UI, Memory & Context, Reasoning & Planning. It’ll be the same experience with Ridgeline!
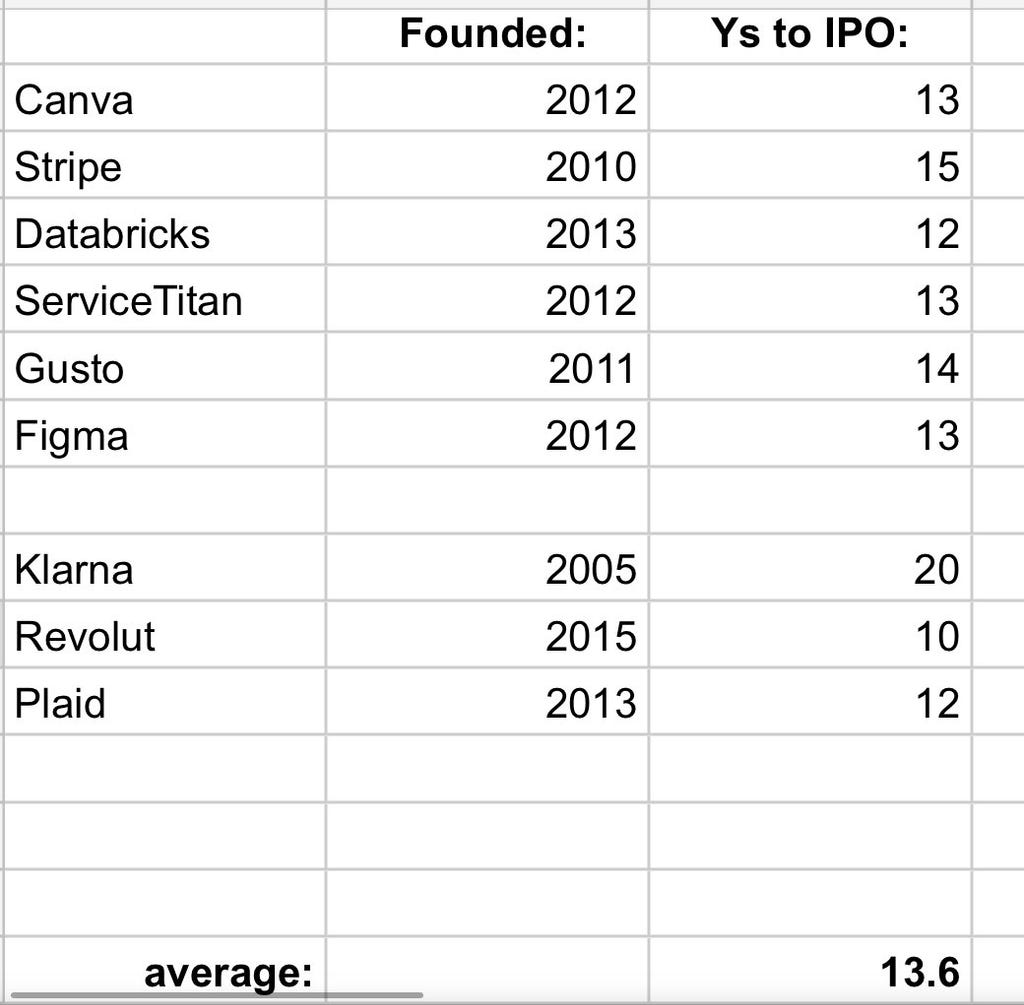
→ Why does it matter? Thanks SaaStr for this chart. These are the top contenders to IPO in 2025. The average # of years since founding is ~13.5.
Tweets that stopped my scroll:

→ Why does it matter? A picture is worth 1,000 words!

→ Why does it matter? Michael J. Mauboussin is one of the great investment researchers! Here is his latest paper!
Pods & YouTubes worth checking out:
→ Why does it matter? When Stan Druckenmiller speaks, investors listen! This is only a ~20-minute interview. Worth a watch! 👀
→ Why does it matter? It’s always a good idea to pay attention to SalesForce.com! Here is an excellent podcast with Marc Benioff explaining AgentForce!
Quotes & Eye Wash:
https://billwear.github.io/art-of-attention.html
The Quiet Art of Attention by Bill Wear
The “it” in AI models is the dataset. - Posted on June 10, 2023 by jbetker
I’ve been at OpenAI for almost a year now. In that time, I’ve trained a lot of generative models. More than anyone really has any right to train. As I’ve spent these hours observing the effects of tweaking various model configurations and hyperparameters, one thing that has struck me is the similarities in between all the training runs.
It’s becoming awfully clear to me that these models are truly approximating their datasets to an incredible degree. What that means is not only that they learn what it means to be a dog or a cat, but the interstitial frequencies between distributions that don’t matter, like what photos humans are likely to take or words humans commonly write down.
What this manifests as is – trained on the same dataset for long enough, pretty much every model with enough weights and training time converges to the same point. Sufficiently large diffusion conv-unets produce the same images as ViT generators. AR sampling produces the same images as diffusion.
This is a surprising observation! It implies that model behavior is not determined by architecture, hyperparameters, or optimizer choices. It’s determined by your dataset, nothing else. Everything else is a means to an end in efficiently delivery compute to approximating that dataset.
Then, when you refer to “Lambda”, “ChatGPT”, “Bard”, or “Claude” then, it’s not the model weights that you are referring to. It’s the dataset.
